Validation: Walk-Forward & Multiverse
The tests that separate a robust algorithm from one overfit to the past. Turn them on before going live.
When the exploration finishes and you see an algorithm with a Sharpe of 3, a 400% return and a ridiculously small drawdown, your natural reaction is excitement. Resist that impulse. Before trading any algorithm with real money, you need to understand the most silent threat in algorithmic trading: overfitting.
Overfitting is the greatest danger in algorithmic trading. An overfit algorithm has «memorized» the specific historical data it was trained on: it learned the noise, not the signal. On new data — the real future — it fails consistently. The problem compounds when you test 10,000 combinations: by pure statistics, some will look great just by luck. Walk-Forward and Multiverse validations exist precisely to unmask them.
Walk-Forward (temporal validation)
The idea is simple but powerful: instead of training and evaluating the algorithm on the same full history, you split time into windows. In each window, the algorithm is «selected» or calibrated on one segment (in-sample) and evaluated on the next segment it has never seen (out-of-sample, OOS). Then the window advances and the process repeats. In the end, only the cumulative performance on the OOS segments matters, because that simulates what would happen in the real future.
[--- train ---][test]
[--- train ---][test]
[--- train ---][test]
[--- train ---][test]
→ se evalúa SOLO en los tramos "test" (datos nunca vistos)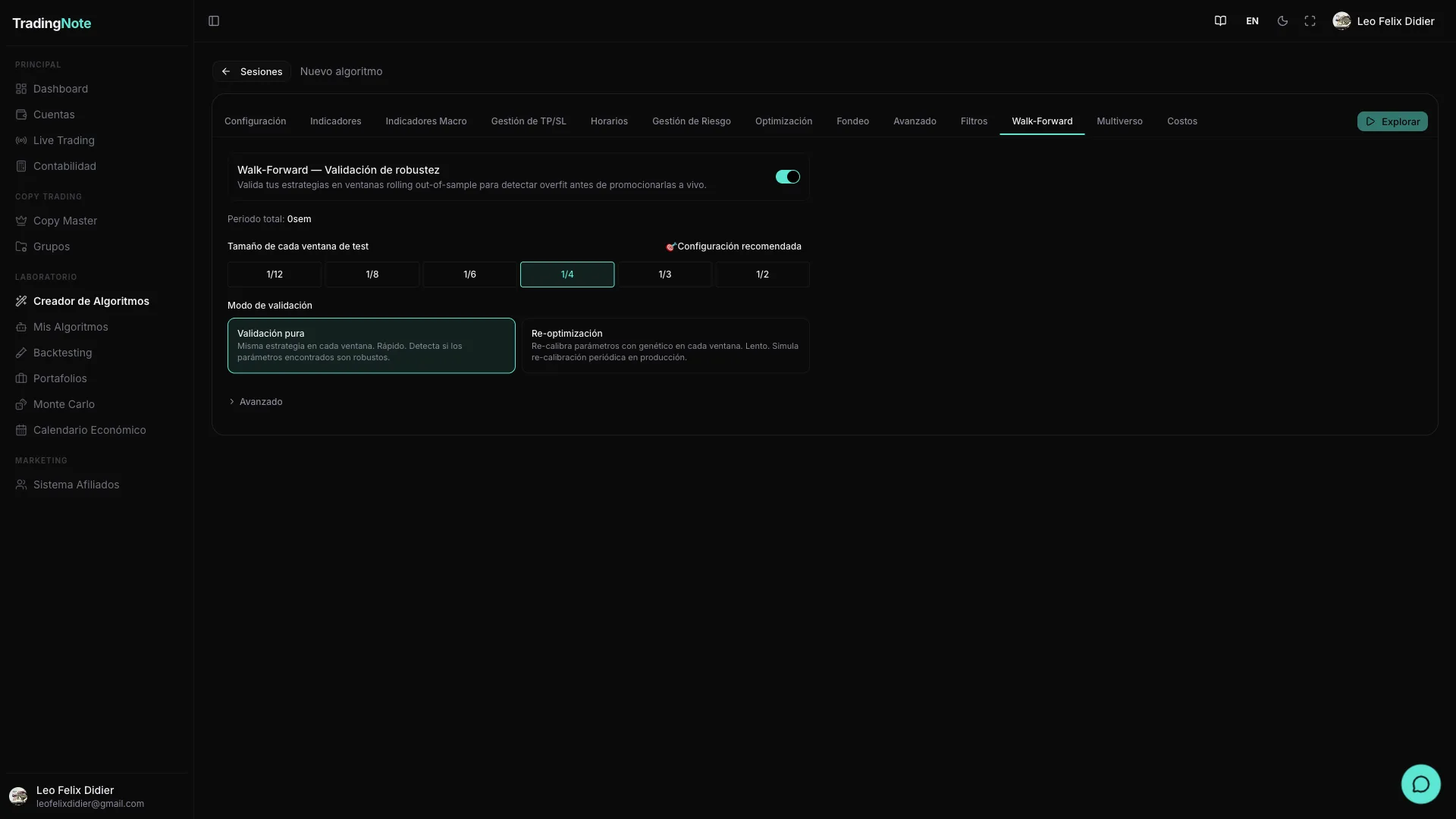
Configuration parameters
| Parameter | Options | Default | What it does |
|---|---|---|---|
| Enable Walk-Forward | Yes / No | No | Enables temporal validation. Off by default to avoid slowing down quick explorations. |
| Test window size (testFraction) | 1/12, 1/8, 1/6, 1/4, 1/3, 1/2 | 1/4 of total | What fraction of the total history is used as «test» in each window. Smaller = more windows and higher granularity; larger = each OOS window lasts longer (better variance estimation). |
| Mode | Validation / Re-optimization | Validation | Validation: tests the same parameters found in the exploration on each OOS window. Re-optimization: recalibrates parameters on each training window before evaluating. Re-optimization is slower but detects if the algo requires frequent adjustments (a sign of fragility). |
| Depth (re-optimization mode) | Fast (5 gen / 20 pop) · Standard (10 / 30) · Deep (20 / 50) | Standard | How much genetic effort is devoted to recalibrating each window. Greater depth = more compute time, but more accurate results. |
| topN | 1 – 50 | 20 | How many of the best strategies from the exploration are subjected to Walk-Forward. Validating all 10,000 combinations would be prohibitive; the top 20 already capture most of the value. |
| Minimum approval filters | WFE ≥ 0.5 · Pass rate ≥ 60% · Sharpe OOS ≥ 0.5 | Enabled | Minimum thresholds for an algorithm to pass WF validation. You can adjust them to your preference, but don't lower them if you don't have experience yet. |
Metrics returned by Walk-Forward
| Metric | Meaning and interpretation |
|---|---|
| WFE (Walk-Forward Efficiency) | OOS performance ÷ in-sample performance. >0.5 signals robustness; near 1 is excellent (the algo doesn't inflate in training); below 0.3 suggests severe overfitting. Don't expect a WFE of 1: there will always be some out-of-sample degradation. |
| Parameter stability | How much the optimal parameters vary from one window to another (in re-optimization mode). If the parameters that work change radically each month, the algo is not stable; if they stay similar, there is a real underlying signal. |
| Degradation slope | If the performance on OOS segments drops window by window, the algo is losing relevance over time (market conditions changed). A steep negative slope is a warning sign. |
| Average OOS Sharpe | Average Sharpe calculated exclusively on the never-seen segments. This is the number closest to what you would get in the real future. An OOS Sharpe ≥ 0.5 is already an honest result. |
| Pass rate | Percentage of OOS windows where the strategy met the minimum criteria. A pass rate of 70% means that in 7 out of every 10 periods the algo behaved as expected. Below 60% is a sign of inconsistency. |
Quick guide for choosing testFraction based on available history: with less than 6 months use 1/4 in validation mode; with 6 to 18 months use 1/4 in re-optimization mode; with more than 18 months you can drop to 1/6 in re-optimization to get more windows and a more reliable degradation estimate.
Multiverse (synthetic validation)
Walk-Forward tells you whether the algorithm held up in the single past that actually occurred. The Multiverse answers a different question: what if the market had taken a different path? Instead of splitting the real history, it generates N statistically coherent «parallel» markets: other paths the price could have traveled with the same volatility, trends and correlations. If your algorithm performs well across hundreds of those alternative universes, it's because it captured something real — not because it exploited an anomaly unique to the specific past you happened to have.
Configuration parameters
| Parameter | Options | Default |
|---|---|---|
| Enable Multiverse | Yes / No | No |
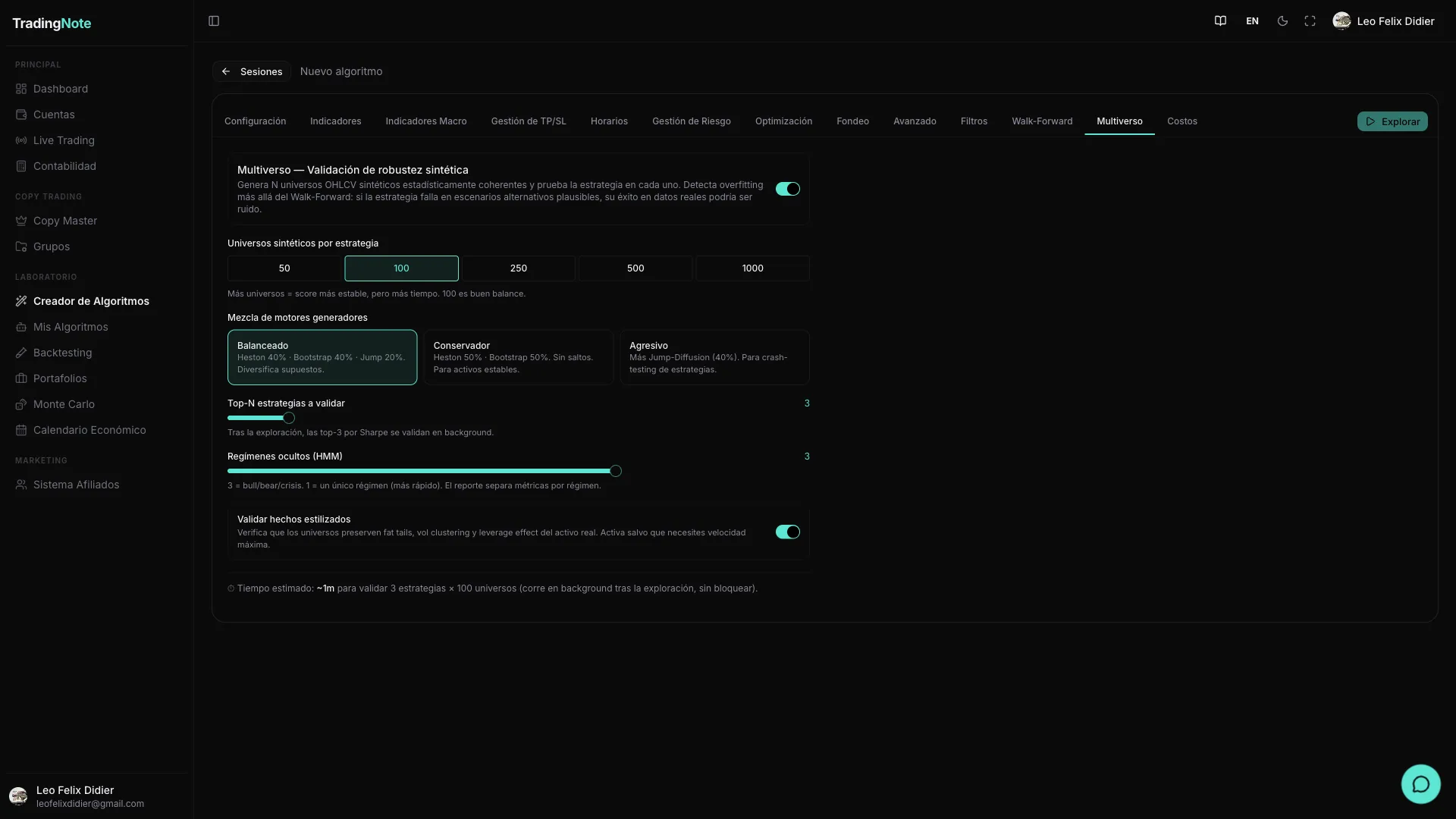
| Number of universes | 50 · 100 · 250 · 500 · 1000 | 100 |
| Engine (enginePreset) | Balanced · Conservative · Aggressive | Balanced |
| topN | 1 – 10 | 3 |
| Number of market regimes | 1 – 4 | 3 (bullish / bearish / crisis) |
| Run additional validators | Yes / No | Yes |
The main result from the Multiverse is a Score from 0 to 100. What each range means:
- Score ≥ 75 — Robust. The algorithm performed consistently across the vast majority of alternative universes. This is the minimum bar to consider trading it live.
- Score 50–74 — Moderate. Works well in some scenarios but not all. It may be valid, but needs more context: what scenarios does it fail in? Are they likely in the near future?
- Score < 50 — Fragile. It only worked in a small fraction of the simulated universes. It most likely captured an anomaly in the specific history. Do not trade it with real money.
DSR and Monte Carlo (related)
Walk-Forward and Multiverse do not act alone. They are part of a four-layer system. The other two are DSR and Monte Carlo, which you will also find in the platform. DSR (Deflated Sharpe Ratio) is applied automatically during exploration: it corrects the Sharpe of each candidate by the number of combinations tested, because if you test 10,000 combos, the expected Sharpe of the best one by pure luck is very high. DSR lowers that threshold statistically and discards those that don't justify their Sharpe given the search size. Monte Carlo analysis — which you can run later on a specific algorithm — does something different: it randomly reorders the actual trades and simulates thousands of possible sequences to stress-test the equity curve and probable maximum drawdown.
The robustness loop
These four layers are not redundant: they are orthogonal. Each one attacks a different axis of overfitting. Together they form the process TradingNote calls the «robustness loop»:
- 1
Genetic exploration
You launch the exploration and the engine tests thousands of combinations of indicators and parameters, keeping the candidates with the best performance on the historical data.
- 2
DSR discards the lucky ones
The Deflated Sharpe Ratio adjusts the statistical threshold by the search size and eliminates algorithms whose Sharpe does not exceed what you would expect by chance when testing so many combinations.
- 3
Walk-Forward verifies the temporal dimension
Confirms that the algorithm held up on segments of the history it did not use for optimization. If performance collapses out-of-sample, the algorithm memorized, not learned.
- 4
Multiverse verifies the scenario dimension
Confirms that the algorithm did not depend on the specific path the market took. If it works across hundreds of alternative synthetic markets, it is robust to the randomness of history.
What survives all four layers deserves your attention. It won't be the most spectacular of the bunch, but it will be honest.
Walk-Forward and Multiverse only run on the topN best strategies because they are computationally expensive operations. Do not expect them to validate all 10,000 combinations from the exploration: the goal is to filter the finalists, not to re-explore the entire space.
Don't fall in love with a high Sharpe without validating. A Sharpe of 4 with a WFE of 0.1 is a classic overfitting trap. A Sharpe of 1.5 with a WFE of 0.7 and a Multiverse score of 80 is gold: that algorithm proved it works outside the data that produced it and in scenarios that never happened.
Once your best candidates have passed the robustness loop, the next step is to explore the results in depth and visualize the exploration in the Neural Explorer. Continue in «Results and Neural Explorer».